
딥러닝에 대한 정리를 시작해보려한다.
딥러닝에 관심을 갖게 된 계기는 이미지처리였고, 궁극적으로 내가 관심있는 자율주행과 관련해서 프로젝트를 해보고 싶어서 공부를 하게되었다.
하지만 알다시피 복잡한 수식과 수학이 있어서 한번에 와닿지는 못하고 여러번 강의도 듣고 책을 정리하면서 이해할 수 있었다.
최종적으로 자율주행 이미지처리를 위해서 한단계씩 내용을 정리할 예정이다.
먼저 MNIST부터 정리할 예정이다.
MNIST는 손으로 쓴 숫자들로 이루어진 대형 데이터이며, 딥러닝 분야(이미지처리)에서 첫 실습으로 많이 사용된다.
여기서 중요한 내용은 숫자 그 자체가 아닌, 컴퓨터가 이미지를 인식하는 방법이다.
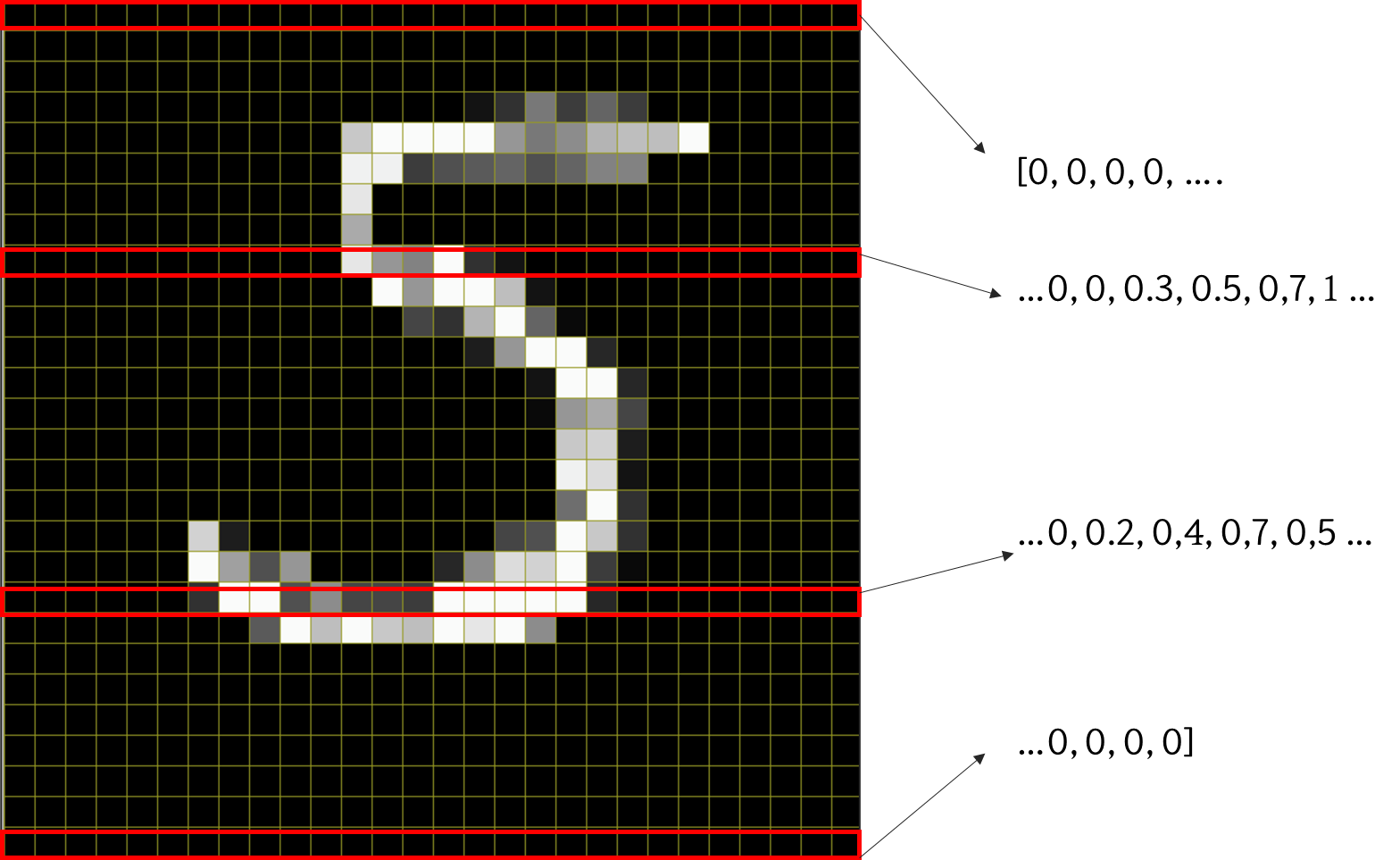
컴퓨터는 어떻게 이미지를 처리할까? 아쉽게도 사람처럼 이건 5다! 를 직관적으로 이해하지 못한다.
그래서 왼쪽 상단부터 오른쪽 하단까지 한줄한줄 차례로 하나의 픽셀을 읽는데, 하나의 픽셀에 담긴 값을 통해 이미지를 이해한다.
위의 그림처럼, 만약 픽셀이 검정색이면0, 흰색이라면 1일 경우 저렇게 한줄 한줄을 0~1 사이의 값으로 읽는다.
MNIST는 28*28 픽셀이기 때문에 총 784개의 픽셀로 구성되어 있으며, 784개의 값을 리스트로 받아서 읽는 것이다.
그래서 예시로 ([0, 0, 0, ..., 0.3, 0.5, 0.6... 1, 0, 0, 0], 5) 이렇게 이미지 값과 목표변수(5)로 구성되어 있다.
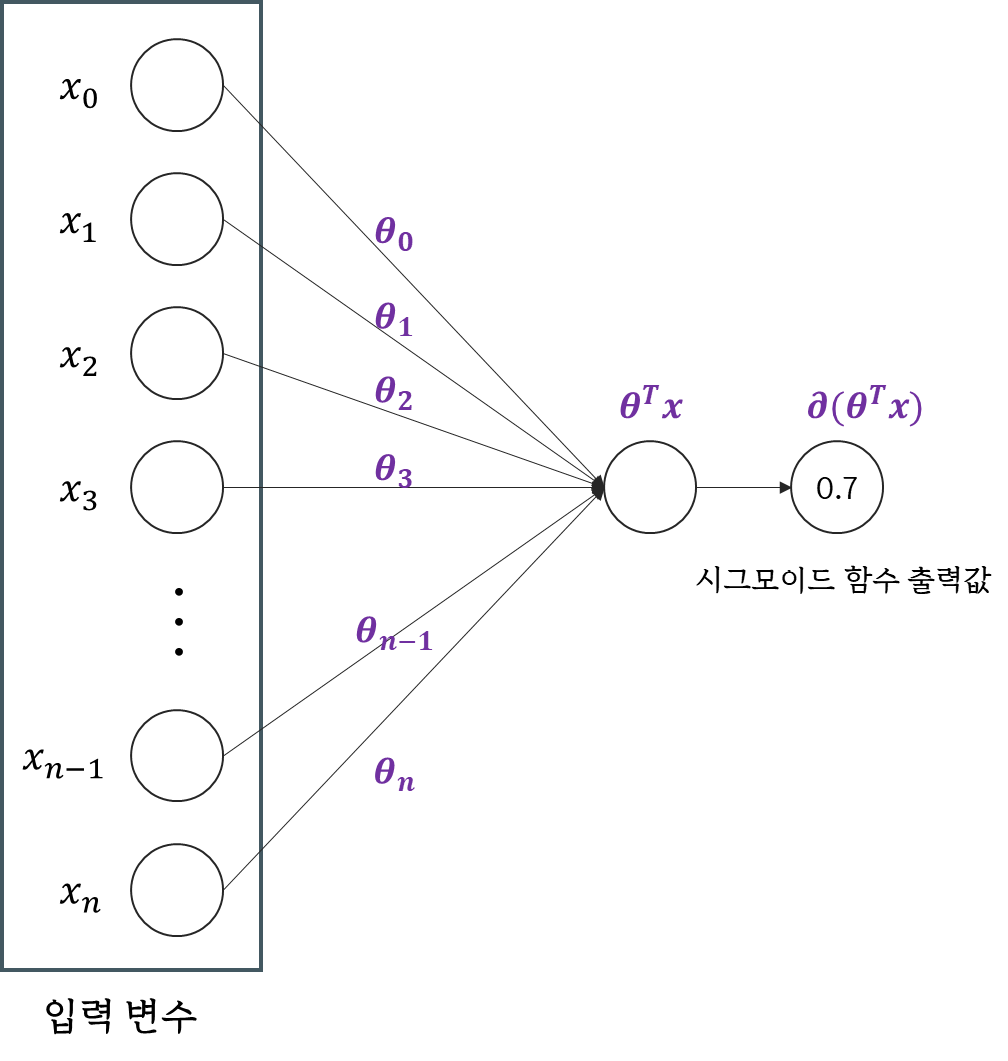
그렇다면 784개의 숫자로 어떻게 5로인식을 하는가? (사실 785이다. X0 포함)
로지스틱 회귀로 예시를 들어보겠다.
각가 입력 변수에는 픽셀의 값이 들어가 있고, 해당 픽셀은 가중치가 곱해져서 합해져 하나의 값으로 계산된다.
그래서 하나의 값을 통해 시그모이드 함수 출력에 따른 최종 값이 나오고, 그 값이 몇 이상일 때 5, 아니면 5가 아니다. 라고 판단을 하는 것이다.
이렇게 학습을 해서 자기 스스로 어떤 데이터가 들어왔을 때, 결정을 할 수 있게 하는 것이다.

그리고 여기서 학습이란, 세타값을 조절함에 따라, 데이터들이 조금 더 정확하게 예측하도록 하는 것이다.
세타값을 정밀하게 조절하기 위해선 여러개의 입력 변수가 필요하겠지? 정말 개떡같이, 사람도 못알아볼 정도의 '5'가 아닌 이상, 일반적인 5의 특징이 있기 때문에, 컴퓨터는 그 특성을 찾아 나가면서 학습(세타값 조절)을 하게 된다.
그래서 딥러닝에서는 다양한 입력변수, 즉 데이터의 양이 중요한 것이다.

'5'를 학습을 했다면, 컴퓨터는 대충 이런 모양의 식을 갖게 된다.
5라고 판단하기 위해서 보라색 영역의 값을 강하게 하고, 파란색도 평균 이상으로 할 것이다. 반대로 회색 부분은 낮추면서
회색에 많은 값이 들어와있다면? 아 이건 5가 아니겠구나!
보라색에 많은 값이 들어와있다면? 아 이건 5일 가능성이 높구나!
이렇게 생각할 수 있도록 학습하게 된다.
0부터 9까지 학습이 된 모델에, 내가 5를 넣었다면 어떻게 판단할까?

더 복잡한 과정이 있겠지만, 쉽게 설명했을 때, 세타값을 따라서 값이 나오고, 이 값을 0부터 9까지의 수 중에서 어디에 적합한지 판단을 하고 그 과정에서 가장 높은 값이 그 숫자라고 판단하는 것이다.
종합하자면, 컴퓨터는 이미지를 안타깝게도 사람이 인식하는 것처럼 인식할 수 없다.
따라서 이미지를 숫자로 인식하고, 숫자로 해석하며, 숫자로 연산해서 판단한다!
'딥러닝' 카테고리의 다른 글
| [인공 신경망] 입력변수, 출력변수 (1) | 2023.11.26 |
|---|---|
| [인공 신경망] 층, 뉴런, 가중치 (0) | 2023.11.23 |
| [인공 신경망] 딥러닝의 구조와 신경계 (0) | 2023.11.21 |


