이번에 정리하는 BeautifulSoup
사실 BeautifulSoup은 예전 크롤링할때부터 많이 써봤는데.. 정작 어떻게 쓰는지를 몰라서 예제만 따라하고 내가 하고 싶은 사이트들은 크롤링 못하고 그랬다.
그래서 이번에 내용을 정리해보면 우선 BeautifulSoup은 HTML문서를 예쁘게 정리하는 라이브러리 정도라고 생각하면 될듯!
즉 복잡한 웹을 이제 html.parser를 활용해서 필요한 태그들을 쏙쏙 가져온다고 보면 되고.
여기에 이제 find와 select를 활용해서 내가 찾고 싶은 내용들을 갖고 온다고 보면 된다!
그러면 find와 select의 차이는 무엇일까?
나도 이렇게 정리하기 위해서 찾아봄 ㅋ
1) find
find는 태그 요소들을 이용해서 찾는 것!!
그래서 사용 예시들을 살펴보면
#예시
infos = soup.find_all('tbody', {'id':'id명'})
#태그명
soup.find('p')이렇게 쓴다. 그래서 내가 tbody를 찾았다는 코드를 보면 find_all을 통해 'tbody' id 까지 넣어서 그!! tbody를 찾아낸 것이다.
2) select
select는 CSS를 이용해서 찾는것!
#class 하나만 갖고 오고 싶을 때
soup.select_one('div.class명')
#여러개를 갖고 오고 싶을 때
soup.select('div.class명')여기서 앞 CSS에서 설명했지만
id는 #, class는 . 등등 약속들이 있다.
그래서 꼬리에 꼬리를 물고가면된다. (이게 너무 재밌음..)
예를들어서
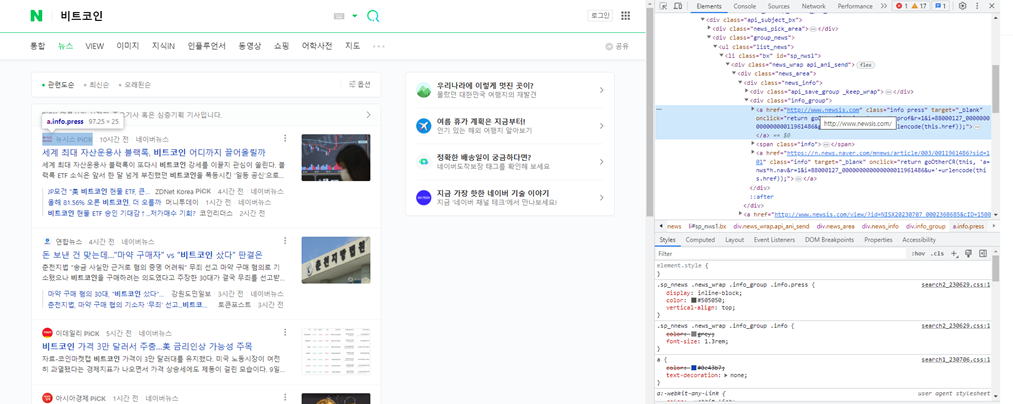
이렇게 발행기관을 확인하고 싶을 때, 구조를 보면

어..엄청 쌓이고 쌓여있다. (카타르시스 지림)
하나씩 찾아보는거다 이럴때.
1) 일단 내가 찾고 싶은 발행기관은 어떤 클래스명인지? 어떤 id명인지? 별명을 찾아보자!
2) 찾았으면 ctrl+f 눌러서 검색을 해본다. 근데 class 명이니까 '.' 을 써야하는데~ 'info press' 처럼 띄어쓰기가 있으면
검색이 안됨! 이럴땐 .을 쓰면 된다(나한텐 엄청 팁이었음..ㅎ)
soup.select_one('.info.press>span').text로 기관명을 충분히 갖고올 수 있다. 만약에 'info press'에 여러개의 span태그로 감싸져 있다면 몇번째 span인지 확인할 필요가 있고
만약에 두번째라면??
soup.select_one('.info.press>span:nth-of-type(2)').text이렇게 'span:nth-of-type(2)'로 가져오면 된다! 이게 먹힐때 아주 기분이 좋음 ㅎ
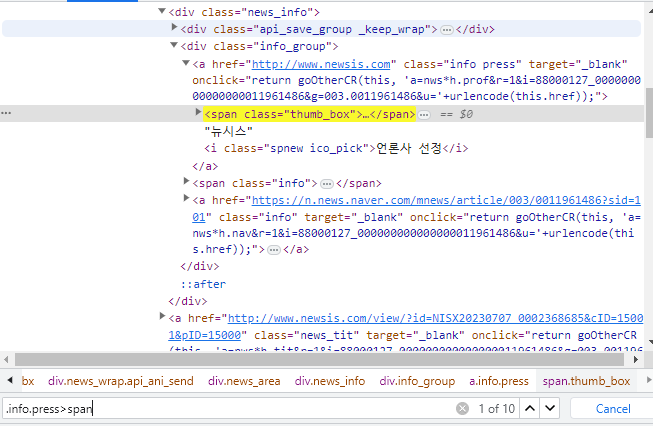
아주 기분이 좋게도 이렇게 딱 노란 형광으로 내가원하는게 똭~ 등장하면 성공!! 진짜 미친다.
이렇게 원하는걸 하나씩 하나씩 가져오면 된당~
아주...재밌어
한페이지에 10개가 있으니 반복문을 돌리면 되고~ 페이지도 넘겨주면 된다! 반복문으로
이제 이런 부분들은 기본적인 파이썬을 할줄 알아야함!!
여담이긴 하지만, 확실히 내가 크롤링에 갑자기 눈을 뜨고 잘하게된 이유도 보면
기본적인 파이썬 실력이 늘어서 그런것 같다.
그전까지는 뭔~~말인지 하나도 이해못했는데 말이쥐
'크롤링' 카테고리의 다른 글
| 내맘대로 크롤링(5): 구조를 좀더 살펴보자~ (0) | 2023.07.21 |
|---|---|
| 내맘대로 크롤링(4): 그래서 BeautifulSoup이 뭔데? (0) | 2023.07.10 |
| 내맘대로 크롤링(2): CSS 선택자의 종류 (0) | 2023.07.09 |
| 내맘대로 크롤링(1): HTML구조와 태그 (0) | 2023.07.09 |
| 내맘대로 크롤링 (0): 크롤링을 하게 된 이유 (0) | 2023.07.09 |