
02. Real Estate Dataset
출처: https://www.kaggle.com/datasets/arnoldkakas/real-estate-dataset/data
Real Estate Dataset
Explore Spatial dynamics, Price, and Quality of Apartments in Slovakia (11/23)
www.kaggle.com
1. 데이터 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('/kaggle/input/real-estate-dataset/Real Estate Dataset.csv',sep=';', on_bad_lines='skip') # if errors occured, skip
df.head()
이번 데이터는 굉장히 raw data가 많았다. 애초에 캐글 설명에도 raw data가 많으니 목적 자체가 '데이터 클리닝'이라고 정의할 정도였다.
또한, csv가 정제되지 않았기 때문에 기존의 코드로 csv를 열 수 없었다.
먼저 csv를 ';'를 활용해 seperate 하고, 몇몇개의 에러가 발생한 행은 skip 하는 식으로 진행했다.
이번 데이터는 null값이 굉장히 많고, 유럽(슬로바키아)의 데이터라서 인코딩이 까다로웠기 때문에 해당부분에 주안점을 두며 데이터를 준비했다.
1) 결측치는 얼만큼이고 어떻게 처리할지?
2) 데이터의 타입을 어떻게 변경해야 할지
3) 라벨 인코더를 활용할 때, 변수는 몇개인지?
4) 데이터의 불균형을 어떻게 처리할 지?
5) 표준화를 진행해야 하는데 이상치 처리는 어떻게 할지?
2. EDA
먼저 전체 데이터의 수를 파악하고, 정보, 결측치를 순서대로 분석했다.
df.shape
df.info()
df.isna().sum()
15,403개의 행과 27개의 피처로 구성되어 있는 데이터셋이었고, 피처가 너무 많다는 생각을 우선적으로 했다.
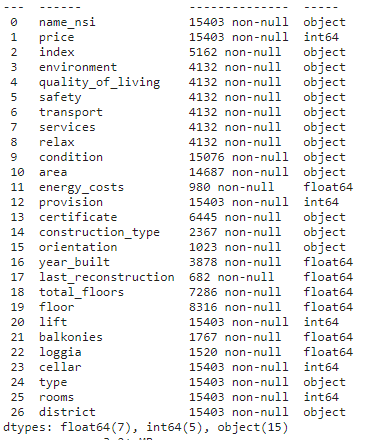
추가적으로 데이터 타입을 변경해야 겠다고 느꼈고, 15,403개의 데이터가 모두 있는 피처가 많지 않았다. 그래서 너무 많은 결측치가 있다면 해당 피처를 과감히 제거해야겠다고 판단했다.

index 부터 relax까지 11,271개의 데이터가 누락되었다. 각 피처의 특성을 보니 자체적으로 평가한 점수(index)의 하위점수들 이었다. 즉, environment, quality_of_livng, safety, transport, services, relax 가 index의 하위 항목들이었고, 결국 이들은 Multicollinearity 가 발생할 것이기 때문에 과감하게 삭제하기로 결정했다.
condition, area를 제외한 나머지 피처도 결측치가 많아 제거하기로 했다. floor, total_floors가 price에 영향을 미칠 것이라 생각해 제거하지 않으려 했다. 10,000개 이상의 null만 제거하려다가, 우선은 최대한 많은 양의 데이터를 보존하기로 결정했다.
참고로 condition, area는 아파트의 환경조건, 면적으로 price에 영향을 미칠 수 있기 때문에 결측데이터만 제거하기로 결정하였다.
del_cols = ['index', 'environment', 'quality_of_living', 'safety',
'transport', 'services', 'relax', 'energy_costs', 'certificate',
'construction_type', 'orientation', 'year_built', 'last_reconstruction',
'total_floors', 'floor', 'balkonies', 'loggia'
]
print(df.shape)
df.drop(del_cols, axis = 1, inplace = True)
print(df.shape)
shape을 통해 코드가 정상적으로 작동했는지 확인하는 것을 잊지 말자.

print(df.shape)
df.dropna(inplace = True)
print(df.shape)
나머지 null 데이터도 제거해준다. 데이터가 훨씬 깔끔해졌다. 여기서부터는 데이터에 대한 지식과 도메인 분야의 지식이 필요하다. 과연 가격에 어떤 변수들이 영향을 미칠 것인가? 다음 변수를 사용할 것인가 말 것인가?
그리고 통계를 한번 봐야한다.
- name_nsi : 지역 이름
- condition: 아파트 상태
- area: 면적
- provision: 대행사 제공 가격 포함여부(0/1)
- lift: 엘리베이터 여부 (0/1)
- cellar: 지하실 여부 (0/1)
- type: 아파트 유형
- rooms: 방의 개수
- district: 커뮤니티가 속한 지구
각각을 고려했을 때, district와 name_nsi는 서로 상관관계가 있을 것으로 판단하였고, nunique를 통해 각각의 변수의 고유값을 확인해보았다.
print(df['name_nsi'].nunique()
print(df['district'].nunique()
598, 79의 값을 확인했고, 어떤 변수를 남길까 고민하다 countplot으로 확인해보기로 했다.
sns.countplot(x = 'district', data = df)
plt.xticks(rotation = 90)
plt.show()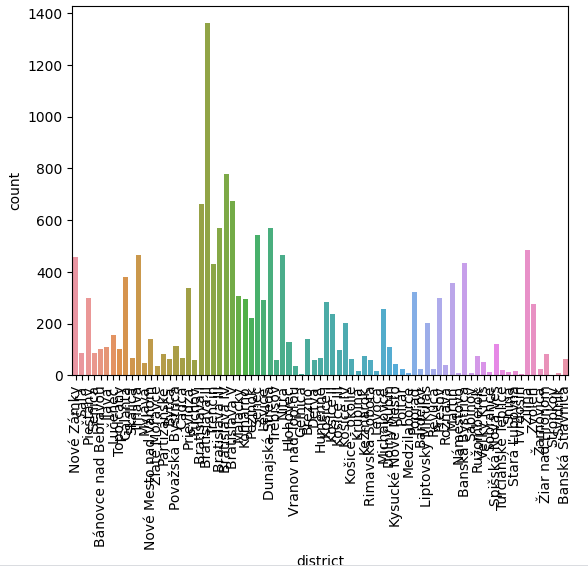
유독 많은 district의 값을 알기 위해 value_counts() 매서드를 활용해 district를 확인했다.
district
Bratislava II 1360
Bratislava IV 778
Bratislava V 673
Bratislava I 661
Bratislava III 571
...
Sabinov 8
Svidník 8
Gelnica 6
Tvrdošín 5
Stropkov 2
Name: count, Length: 79, dtype: int64
Bratislava 지역이었는데, 해당 지역에 집중적으로 부동산이 집중된 것을 확인했다. 가격에 영향을 미칠 것으로 파악했다. 'name_nsi' 예상한대로 district에 포함되는 개념이기 때문에 제거하기로 결정했다.
다음으로 'area'타입이 string으로 되어 있어서 int로 변경하고자 했다.
하지만 큰 문제가 발생했는데, 바로 area에 '76,5'라고 오타가 난 데이터가 존재했다. 아마 76이든, 75이든 또는 76.5이든 입력 과정에서 오류가 난 것으로 판단했다.
따라서 이를 고치기 위해 ',' 를 '.' 으로 변경하고, 해당 값을 실수로 변경 후, int 로 변경했다.
df['area'] = df['area'].str.replace(',', '.') #,를 .으로 바꿔서 76.5로 변경
df['area'] = pd.to_numeric(df['area'], errors = 'coerce') # 혹시 에러가 나면 대체(NAN 같은)
df['area'] = df['area'].astype(int)
기본적인 EDA를 진행하면서 이상치를 제거하는 과정을 거쳤다.
target인 'price'의 이상치를 살펴보기 위해 histplot을 살펴보았다.
sns.histplot(x = 'price', data = df)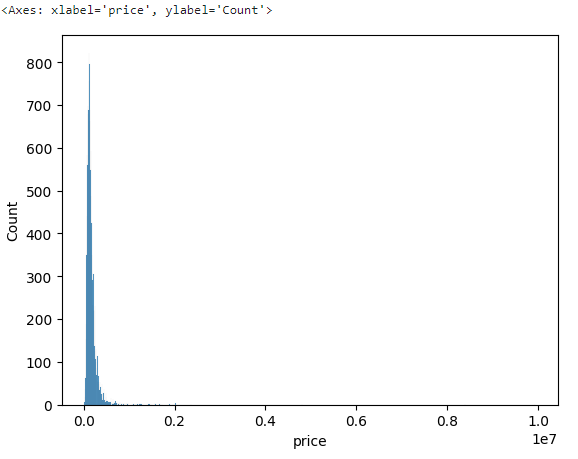
값이 하나가 매우 크거나, 몇 개가 크게 도출된 것으로 생각하여 이를 구체화 하기 위해 rugplot을 그렸다. rugplot을 활용하면 outlier를 쉽게 볼 수 있다.
sns.rugplot(x = 'price', data = df)
역시 몇 개의 값이 크게 잘못 되어 있는 걸 확인했고, 4,000,000 이상의 값을 제거하기로 결정했다.
print(df.shape)
cond = df['price'] < 4000000
df = df[cond]
print(df.shape)
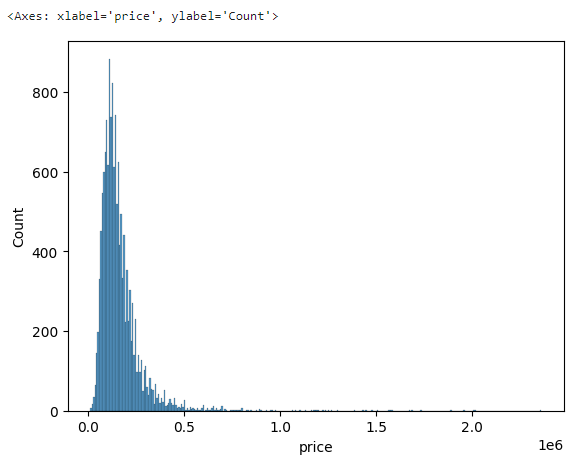
하지만 여전히 분포가 좌측에 몰려있었다. 조금 더 전처리가 필요할까 싶어, 1,000,000 이상의 price를 추출했는데 특정 지역의 'New building'만 추출이 되었다. 아무래도 해당 지역의 값이 유독 비싼 것으로 판단되어 의미있지 않을까 싶어 그대로 진행하기로 했다.

다음으로 condition의 countplot을 그렸을 때, Development project가 너무 부족했다. 가장 많은 값과는 60배 이상의 차이가 발생해서, 해당 값 역시 제거하는 게 낫다고 판단했다.
하지만 큰 문제는 'area'에서 발생했다. 'area'에 값이 너무 차이가 커서 실행이 되지 않는 문제가 발생했다.
특히 상위 4건이 말도 안되게 커져 해당 부분을 제거하기로 했다.
하지만 여전히 데이터의 격차가 너무 컸고, rugplot으로 이를 구체화했다.

다음으로 provision을 봤는데 역시 데이터의 불균형이 너무 심했다. 하지만 'cellar'는 99%이상 편중이 발생했기 때문에 cellar를 제거하고, provision은 그대로 진행했다.

3. 데이터 전처리(피처 엔지니어링)
라벨 인코더로 범주형 컬럼을 수치화시켜주는 과정을 거쳤다.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
cat_cols = ['condition', 'type', 'district']
for col in cat_cols:
df[col] = le.fit_transform(df[col])
df.head()
그리고 area의 값을 표준화하였다.
from sklearn.preprocessing import StandardScaler
num = ['area']
scaler = StandardScaler()
df[num] = scaler.fit_transform(df[num])
이후 X, y 값으로 독립변수, 종속변수를 분리하였다.
y = df.pop('price')
X = df
4. 모델 학습
모델학습을 하기 위해 train, test를 분리하는 과정을 거쳤다.
데이터의 수가 충분하기 때문에 test size는 0.3으로 설정해주었다.
학습은 xgboost와 RF를 선정했고, 파라미터는 xgboost만 임의의 값으로, rf는 설정하지 않았다.
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(X, y, test_size = 0.3, random_state = 123)
from xgboost import XGBRegressor
model_xgb = XGBRegressor(random_state = 123, max_depth = 5, n_estimators = 150, learning_rate = 0.01)
model_xgb.fit(X_tr, y_tr)
from sklearn.ensemble import RandomForestRegressor
model_rf = RandomForestRegressor(random_state = 123)
model_rf.fit(X_tr, y_tr)
5. 모델 평가
MAE와 RMSE로 모델 평가를 진행했다.
from sklearn.metrics import mean_absolute_error, mean_squared_error
from math import sqrt
pred_xgb = model_xgb.predict(X_val)
print('XGB MAE:', mean_absolute_error(y_val, pred_xgb))
print('XGB RMSE:', sqrt(mean_squared_error(y_val, pred_xgb)))
pred_rf = model_rf.predict(X_val)
print('RF MAE:', mean_absolute_error(y_val, pred_rf))
print('RF RMSE:', sqrt(mean_squared_error(y_val, pred_rf)))
확실히 회귀모델은 평가에 대한 판단이 어려운 것 같다.
이번 실습은 데이터 전처리가 굉장히 까다로웠다. 특히 이상치가 많았고 raw 데이터가 많아 어떻게 처리할지 고민이 많았다. 도메인 지식이 더 풍부했으면 좋은 변수를 선정했을 것 같다. district를 others로 묶는다던가.
'파이썬 데이터분석' 카테고리의 다른 글
| [04] Jobs and Salaries in Data Science (1) | 2024.01.25 |
|---|---|
| [03] Wine Dataset for Clustering (1) | 2024.01.20 |
| [01] Apple Quality (0) | 2024.01.18 |


