
03. Wine Dataset for Clustering
출처: https://www.kaggle.com/datasets/harrywang/wine-dataset-for-clustering
Wine Dataset for Clustering
Cluster wines based on their chemical constituents
www.kaggle.com
1. 데이터 불러오기

이번 실습은 클러스터링을 위한 실습으로, 자료가 사전에 정제되어 있었다.
기초통계, 결측치를 살펴보았을 때, 이상이 없었기 때문에 바로 군집분석을 진행했다.
2. K-Means
군집분석을 위해 이번 실습에서는 K-Means와 HDBSCAN을 모델을 선정하였다.
중심기반(Centroid)의 K-Means와 밀도기반(Density)의 HDBSCAN으로 군집분석을 진행해보았다.
from sklearn.cluster import KMeans
distortions = []
km_range = range(1, 6)
for i in km_range:
model_km = KMeans(n_clusters = i)
model_km.fit_predict(df)
distortions.append(model_km.inertia_)
plt.plot(km_range, distortions, marker = 'o')
K-Means의 핵심은 바로 K 찾기 이다.
몇 개의 군집으로 분석을 진행할 것인지 찾아야한다. 그래서 여러 군집을 형성해보고, '이 군집이 가장 잘 표현하고 있네
'를 판단할 수 있어야 하며 엘보우 메소드(Elbow Method)를 활용하면 최적의 k를 찾을 수 있다.
해당 코드를 보면, inertia를 통해 최적의 k를 찾았는데, intertia란 군집의 중심점과 군집의 샘플 간의 거리 제곱 합을 뜻한다.
즉, 군집이 많으면 많을수록 군집의 크기가 작아지니까 거리가 짧아지니 intertia가 작아질 것이다.
하지만 군집이 많은 것이 무조건 분류를 잘했다고 볼 수 없다.
가장 최적화되어 군집은 inertia의 그래프가 급감하여 다음부터는 inertia가 크게 개선되지 않아 효율이 떨어지는 직점의 k로 설정하는 것이 가장 적절하다.

보면 inertia의 값이 k가 1에서 2로 갈 때, 급감하는 것을 확인할 수 있다. 육안으로 봤을 땐, 2가 가장 적절해보인다.
from yellowbrick.cluster import KElbowVisualizer
model_km = KMeans()
vis = KElbowVisualizer(model_km, k = (1, 11))
vis.fit(df)
vis.poof()
하지만 이를 조금 더 시각화하여 제공하는 라이브러리가 있다. KElbowVisualizer를 활용하면, 학습 속도, 최적화된 클러스터의 수를 제공한다.

해당 라이브러리를 활용했을 때, 3개의 군집이 최적이라는 결론이 나타났다.
그리고 이를 활용해서, 실루엣 계수(Silhouette Coefficient)를 확인할 수 있다.
실루엣 계수란 군집 내 각 샘플들이 얼마나 가깝게 군집을 형성했는지, 그리고 상대군집과 얼마나 멀리 떨어져 있는지 나타내는 계수로, 좋은 군집이란 내부적으로는 가깝게, 외부적으로는 멀리 떨어져 있는 것을 뜻한다.
실루엣 계수는 -1과 1 사이의 값을 갖고, 해당 계수에 대한 평가는 그림과 같다.

이 또한, 시각적으로 볼 수 있는 라이브러리가 존재하며 해당 모델의 실루엣 계수를 시각화해보았다.
from yellowbrick.cluster import SilhouetteVisualizer
km_range = (2, 4)
for i in km_range:
model_km = KMeans(n_clusters = i)
svs = SilhouetteVisualizer(model_km)
svs.fit(df)
svs.poof()
앞서 Elbow Method에서는 k가 2일 때, inertia가 급감하는 것을 보았기 때문에 2가 최적의 군집이 아닐까? 하는 의문이 있었다. 반면 visualizer는 3이 최적의 군집으로 평가했다. 따라서 2, 3을 모두 설정하여 실루엣 계수를 평가해 보았다.


분명 계수는 k=2일 때, 더 뛰어난 것을 확인할 수 있다.
하지만 면적을 봤을 때, 군집 크기의 불균형이 발생한 것을 볼 수 있다.

군집분석에서 판단할 때, 각 군집의 크기가 적절히 분배되는 것이 좋은지 또는 균등한 군집이 좋은지 판단할 필요가 있다.
군집분석은 비지도 학습이기 때문에 정답을 모른다. 따라서 해당 도메인에 대한 충분한 지식이 필요하다.
from sklearn.metrics import silhouette_score
silhouette_score(df, labels=model_km.labels_, metric='euclidean')0.57115661299676653. HDBSCAN
다음으로 HDBSCAN으로 군집분석을 진행했다.
HDBSCAN이란 Hierarchical Density-Based Spatial Clustering of Applications with Noise의 약자로 밀도 기반의 군집분석을 진행하는 것이다. 중요한 파라미터는 최소 군집수 이다. DBSCAN은 eps(Epsilon, 이웃거리 수)가 중요한 파라미터였지만, HDBSCAN은 다양한 eps값을 사용하므로 더욱 기하학적인 패턴에서도 훌륭한 성능을 보인다.
DBSCAN과 마찬가지로 클러스터 모양의 가정이 없다. (K-Means는 원을 가정)
또한, 이름에서도 알듯이 Noise를 잘 처리한다.
DBSCAN의 비해 다양한 밀도, 복잡한 분포에서 활용이 가능하며 파라미터 설정이 DBSCAN보다 쉽다는 장점이 있다.
하지만 알고리즘이 복잡하므로 대용량데이터에서 활용 시 많은 시간이 소요된다는 점과, 클러스터의 밀도가 너무 다르다면, 좋은 분류가 되지 못한다는 한계가 있다.
import hdbscan
array_hdb = df.values # df to array
for m in range(2, 11):
model_hdb = hdbscan.HDBSCAN(min_cluster_size = m, min_samples = None, prediction_data = True).fit_predict(array_hdb)
df['hdb_label'] = model_hdb
dict_hdb = dict((x, list(model_hdb).count(x)) for x in set(model_hdb))
outlier = dict_hdb[-1]
sns.scatterplot(x = 'Alcohol', y='Proline', data = df, hue = 'hdb_label', palette = 'Set1')
plt.show()
print(f"outlier_counts: {outlier}")
HDBSCAN 라이브러리를 먼저 설치해주고, import 하였다.
HDBSCAN은 데이터프레임이 아닌 배열의 형태로 학습이 되어야 하므로 데이터 프레임을 array로 변경했다.
그리고 클러스터의 최소 크기를 설정해서 for 문을 돌렸다.
최소한의 크기보다 작은 것은 noise로 처리하는 것인데, 값이 작을수록 클러스터의 수가 증가하고 내부의 데이터 수가 줄어든다. 2를 예시로 들면, 최소 2개를 하나의 군집으로 살펴본다는 것으로 많은 군집이 형성될 수 있다.
반대로 11의 경우, 최소 11개가 하나의 군집이기 때문에 군집의 수가 줄어든다.
따라서 이 값을 적절히 조절해야 최적의 군집분류가 이루어 진다.

2개일 때, 엄청 많은 군집이 형성된 것을 볼 수 있다.
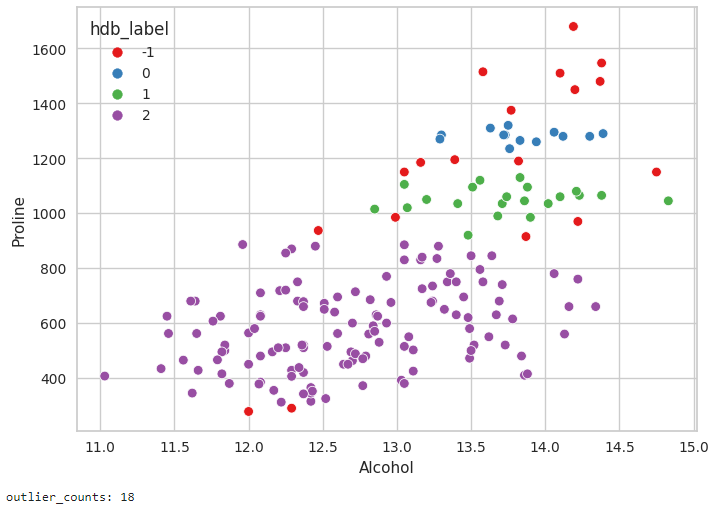
최소한 11개가 되어야 할 때, 군집이 비교적 잘 형성되었다. 3개의 군집(0, 1, 2)이 형성된 것을 볼 수 있고, 앞서 K-Means와 는 다른 군집이 형성되었다.
보다 HDBSCAN이 기하학적 분포를 잘 나타내는 모습이다. 하지만, 실루엣 계수를 보았을 때, 점수가 그렇게 높지는 않았다.
model_hdb = hdbscan.HDBSCAN(min_cluster_size = 4).fit_predict(array_hdb)
silhouette_score(df, model_hdb)0.4380766587683812
전반적으로 군집분석을 진행했을 때, 도메인에 대한 충분한 선수 지식이 필요해보인다. 단순하게 군집으로 클러스터화 하는 것이 아닌, 어떤 기준에서 해당 군집이 생성됐는지 이해할 때 비로소 군집분석의 의의가 있다고 생각한다.
'파이썬 데이터분석' 카테고리의 다른 글
| [04] Jobs and Salaries in Data Science (1) | 2024.01.25 |
|---|---|
| [02] Real Estate Dataset (0) | 2024.01.18 |
| [01] Apple Quality (0) | 2024.01.18 |


